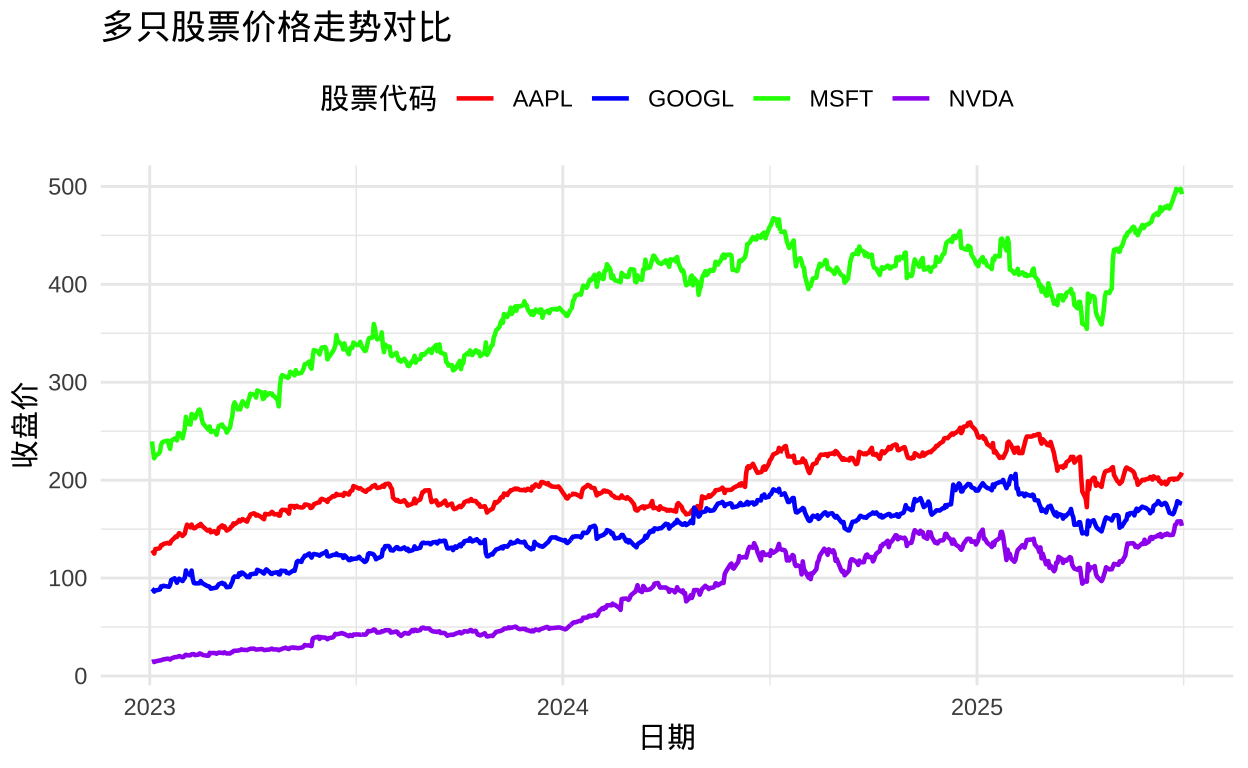
并非有效的市场
安德瑞·史莱佛撰写 《并非有效的金融市场》 的核心目的在于对传统金融领域的 有效市场假说 (EMH)提出系统性批判。史 莱佛通过大量实证研究与逻辑推演,打破了金融市场是完全理性、信息充分且价格能即时反映所有有效信息的经典认知,本书的议题围绕市场无效性的根源、表现形式及对投资实践的启示展开,为我们理解金融市场的复杂性、非理性提供了全新视角,尤其对主动投资策略的合理性提供了理论支撑。
本书并非全盘否定金融市场的合理性,而是指出有效市场只是理论抽象的理想状态,现实市场中存在诸多扭曲价格的因素,这些因素共同构成了市场无效的基础,也为投资者创造了获取超额收益的可能。
对“有效市场假说”的批判
有效市场假说的核心逻辑是:市场参与者是完全理性的,信息能无成本、即时地被所有参与者获取,因此资产价格始终等于其内在价值,投资者无法通过主动分析获得超额收益。
史莱佛从三个维度对这一假说提出反驳:
1.市场参与者并非完全理性——非理性行为的普遍性
史莱佛结合行为金融学的研究成果,指出现实中的投资者普遍存在“有限理性”特征,而非经典理论中的“完全理性人”。投 资者的决策往往受到情绪、认知偏差、从众心理等因素影响,而非纯粹基于对信息的客观分析。
书中列举的典型非理性行为包括:锚定效应(以某一初始价格为基准判断资产价值,忽视真实基本面)、羊群效应(盲目跟随大众投资决策,导致市场过度反应)、过度自信(高估自身分析能力,导致频繁交易与决策失误)。
这些非理性行为并非个别现象,而是形成了群体合力,最终导致资产价格偏离内在价值,形成市场泡沫或过度下跌。
2.信息存在不对称与传递成本——信息并非完全充分
有效市场假说假设“信息免费且即时共享”,但现实中信息存在显著的不对称性:内部人(如企业管理层、核心机构投资者)往往掌握比普通投资者更全面、准确的信息,且信息传递过程中存在时间差、解读成本等问题。普通投资者不仅难以第一时间获取信息,还可能因专业能力不足对信息产生误读。
通过实证数据证明,信息不对称会导致资产价格对信息的反应滞后或过度:部分机构利用信息优势提前布局,待信息公开后获利离场,而普通投资者则可能在价格波动的末端跟风,成为损失的承担者。这 种信息壁垒直接打破了“价格即时反映所有信息”的有效市场前提。
3.市场存在交易成本与制度缺陷——价格无法即时调整至合理水平
有效市场假说忽略了交易成本(如手续费、税费、流动性成本)与制度设计对市场的影响。现 实中,即使投资者发现了价格与价值的偏离,也可能因交易成本过高、市场流动性不足或制度限制(如做空机制不完善)而无法及时通过交易修正价格,导致价格扭曲长期存在。
此外,制度缺陷还可能引发“非理性的市场定价”,例如退市机制不健全导致劣质资产长期占据市场资源,政策干预的不确定性引发市场恐慌或盲目乐观,这些因素都让市场难以自发达到“有效均衡”。
市场无效性的典型表现与案例佐证
史莱佛通过多个经典金融市场案例,直观呈现了市场无效性的具体表现,其中最具代表性的包括:
1.股市泡沫与崩盘:非理性情绪驱动的价格偏离
书中详细分析了互联网泡沫(20世纪90年代末)、美国次贷危机前的房地产泡沫等案例。以互联网泡沫为例,当时大量缺乏盈利支撑、甚至没有明确商业模式的互联网企业,股价被疯狂炒作,市盈率远超合理水平,这并非基于企业内在价值的理性定价,而是源于“对新技术的盲目乐观”“从众投机”等非理性情绪的叠加。最终泡沫破裂,股价暴跌,证明市场价格并未反映资产的真实价值。
2.小盘股效应与价值股效应:被忽视的定价偏差
史莱佛通过长期数据追踪发现,小盘股(市值较小的公司股票)和价值股(市盈率低、市净率低的股票)在长期内的收益率显著高于大盘股和成长股,这一现象无法用有效市场假说解释——若市场有效,这种收益率差异应通过套利行为迅速消失。
史莱佛认为,小盘股被忽视是因为机构投资者因资金规模限制不愿关注,价值股被低估则是因为投资者过度追捧成长股的“美好预期”,忽视了价值股的真实盈利能力。这种定价偏差的长期存在,直接证明了市场的无效性。
3.金融衍生品市场的定价扭曲:复杂工具加剧市场无效
在金融衍生品(如期权、CDO等)市场,史莱佛指出,由于产品结构复杂,投资者难以准确评估其内在价值,往往依赖简化的定价模型(如布莱克-斯科尔斯模型),而这些模型的前提假设(如无风险利率恒定、波动率稳定)与现实市场存在差异,导致衍生品定价出现严重偏差。次贷危机中,CDO等衍生品的错误定价就是引发危机的重要原因之一,凸显了复杂市场中无效性的放大效应。
书籍带来的投资启示与实践建议
基于对市场无效性的论证,史莱佛并非倡导“盲目投机”,而是为投资者提供了基于“市场无效”的投资逻辑,核心启示包括:
1.主动投资策略具有合理性,精选价值是核心
既然市场存在定价偏差,投资者就可以通过深入分析企业基本面(如盈利能力、资产负债表、行业竞争力),发现被低估的资产,通过长期持有获取超额收益。这与有效市场假说倡导的“被动指数投资”形成鲜明对比,为主动管理型基金的存在提供了理论依据。
2.警惕非理性情绪,坚持逆向投资
市场无效的核心驱动力之一是群体非理性,因此投资者应避免跟风从众,在市场过度乐观(泡沫期)保持冷静,在市场过度悲观(恐慌期)积极寻找被错杀的优质资产。逆向投资的本质,就是利用市场的非理性偏差获利。
3.重视信息优势与研究能力,降低信息不对称风险
对普通投资者而言,应通过提升专业能力、深入研究行业与企业,减少对“二手信息”的依赖,尽可能降低信息不对称带来的劣势;同时,要警惕“内幕信息”陷阱,坚守合规投资的底线。
4.合理评估交易成本与流动性,避免盲目套利
即使发现了价格偏差,也需评估交易成本、流动性等因素——若套利成本过高或无法及时变现,定价偏差可能长期存在,甚至导致套利失败。因此,投资决策需综合考虑“价值偏差”与“实现收益的可行性”。
5.投资者形态模型简单分析与适配建议
书籍虽未直接提出“投资者形态模型”,但结合其对市场参与者非理性行为的分析,可提炼出三类核心投资者形态及适配策略:一是“理性套利型”,这类投资者具备专业研究能力,能精准识别价格与价值的偏离,可通过前文提及的主动价值投资策略获利,但需规避交易成本过高、流动性不足的套利陷阱;二是“噪声交易型”,这类投资者易受情绪、短期信息影响,是市场无效性的主要推动者,需警惕自身的认知偏差,通过建立长期投资框架、减少频繁交易规避损失;三是“被动跟随型”,这类投资者缺乏专业分析能力,若盲目跟随市场情绪易成为损失承担者,可在理解市场无效性的基础上,选择兼顾主动筛选与风险分散的投资产品,而非单纯被动跟踪指数。简 言之,投资者需先明确自身形态特征,再结合市场无效性规律制定适配策略,才能降低非理性决策带来的风险。
投资者心态模型分析
结合《并非有效的金融市场》对市场参与者有限理性的核心论述,可提炼出三类与市场无效性紧密相关的投资者心态模型,这些心态是导致资产价格偏离内在价值的关键心理动因,也为理解投资决策偏差提供了核心视角:
1.贪婪与恐惧驱动的情绪主导心态
这是书中重点强调的非理性心态核心,也是市场泡沫与恐慌形成的主要推手。在贪婪心态主导下,投资者会过度关注短期收益,忽视资产基本面的真实价值,如互联网泡沫时期对新技术企业的盲目追捧、比特币等虚拟资产的投机热潮,均是贪婪心态引发的“追涨”行为;而在恐惧心态主导下,投资者会因市场短期波动、负面信息过度反应,出现“割肉出逃”的非理性抛售,导致资产价格被过度低估,例如次贷危机中优质企业股票随市场整体暴跌的现象。这种心态的本质是“短期情绪凌驾于长期价值判断”,打破了有效市场假说中“理性定价”的前提。
2.过度自信的认知偏差心态
书中明确指出,过度自信是多数投资者的共性心态,也是导致频繁交易、决策失误的重要原因。这类心态模型的核心特征是投资者高估自身的信息解读能力、择时能力和风险控制能力,认为自己能超越市场平均水平。例如,部分投资者仅凭碎片化信息就做出投资决策,忽视市场的复杂性和信息的不完整性;还有些投资者频繁调整持仓,认为能精准把握市场波动,最终却因交易成本增加、决策失误导致收益受损。过度自信心态会放大个体非理性行为,进而形成群体层面的定价偏差,加剧市场无效性。
3.锚定与从众的惯性依赖心态
锚定心态与从众心态常相互交织,共同影响投资者决策。锚定心态表现为投资者将某一初始信息(如历史最高价、近期平均价、权威机构的预测值)作为“锚点”,固化对资产价值的判断,忽视后续基本面的变化,例如投资者因某只股票历史最高价较高,就认为当前价格仍“有上涨空间”,无视企业盈利下滑的现实;从众心态则是投资者盲目跟随大众决策,认为“多数人的选择一定正确”,这种心态会形成“羊群效应”,导致市场价格向同一方向过度偏离,如某类主题基金的扎堆申购、某只股票的集中炒作,均是从众心态的体现。这 两种心态的核心是“放弃独立思考,依赖外部信号或群体共识”,进一步强化了市场的无效性。
从实践意义来看,识别这些心态模型是规避投资失误的关键。书中隐含的应对逻辑是:投资者需建立“心态自检机制”,在决策前区分“情绪驱动”与“价值驱动”,通过长期投资框架、基本面分析工具对冲心态偏差,同时警惕锚定信息的局限性和群体决策的盲目性,避免成为加剧市场无效性的“噪声交易者”。
4.投资者心态模型的转换路径与实践要点
基于书中对投资者非理性行为的批判,心态模型并非固定不变,从非理性心态向理性心态的转换,是降低投资决策偏差、利用市场无效性获利的核心前提。具体转换路径可分为三个核心阶段:
第一阶段:心态觉醒与偏差识别。这是转换的基础,核心是投资者主动意识到自身的心态局限。可通过“决策复盘”实现:每次投资决策后,记录决策时的核心依据、情绪状态(如是否受市场热点、他人建议影响),对照前文三类非理性心态模型,标注是否存在情绪主导、过度自信或锚定从众的倾向。例如,若某笔投资是因“看到身边人都在买”而跟风,即可明确识别为“从众心态”,为后续修正提供靶向。
第二阶段:工具对冲与行为约束。针对识别出的心态偏差,借助具体工具建立行为边界,避免非理性情绪主导决策。对应不同心态的对冲工具的:针对“情绪主导心态”,可建立“止损/止盈规则”和“冷静期机制”,如遇到市场剧烈波动时,强制暂停交易24小时再决策;针对“过度自信心态”,可采用“组合投资策略”,通过分散投资降低对自身“择时/选股能力”的过度依赖,同时限制单只资产的持仓比例;针对“锚定从众心态”,可建立“基本面分析清单”,将资产的盈利能力、估值水平等核心指标作为决策核心,而非依赖历史价格、群体共识等锚点信息。
第三阶段:长期强化与习惯养成。心态转换的关键是形成稳定的理性决策习惯,而非单次修正。可 通过“长期投资目标锚定”实现:明确自身的投资周期(如3年、5年)和核心目标(如资产保值、子女教育储备),将短期市场波动与长期目标脱钩,减少因短期情绪波动导致的非理性操作。同时,定期更新对市场无效性的认知,结合书中的案例与实证研究,强化“理性定价优于情绪定价”的认知,逐步弱化非理性心态的影响。
需要注意的是,心态模型转换并非“完全摒弃情绪”,而是实现“情绪可控、理性主导”的平衡。书 中强调,现实中的投资者难以达到绝对理性,但通过持续的觉醒、对冲与强化,可无限接近理性心态,进而在市场无效性中找到精准的投资机会。
个人感悟与思考
读完《并非有效的市场》,更坚定我对“市场并非完全有效”的认知,理解了金融市场的本质是“理性与非理性的交织体”。有 效市场假说作为简化的理论模型,为我们理解市场提供了基准,但现实市场的复杂性远超出理论范畴,这也正是金融市场的魅力所在。
对个人投资者而言,这本书的启示在于:不要盲目相信“市场永远正确”,也不要过度自信于自己的“择时能力”。真 正有效的投资,应该是“基于基本面的价值判断”与“对市场情绪的理性规避”相结合——既通过深入研究发现价值,又通过逆向思维避开泡沫。同时,这本书也提醒我们,金融市场的稳定需要完善的制度设计(如信息披露制度、退市机制、做空机制)来降低无效性,保护普通投资者的利益。
此外,书中的观点也并非绝对,市场无效与相对有效之间可能存在动态平衡:在某些成熟市场、某些时段,市场可能接近有效;而在新兴市场、市场剧烈波动期,无效性则更为显著。因此,投资者需要根据具体市场环境灵活调整投资策略,而非机械套用某一理论。
总结
《并非有效的市场》通过对有效市场假说的系统性批判,揭示了金融市场的无效性本质,其核心观点在于:市场参与者的有限理性、信息不对称、交易成本与制度缺陷,共同导致资产价格偏离内在价值,市场无法自发达到有效均衡。